
One of the following Snowflake features or a third-party data integration tool (not shown) loads data continuously into a staging table:
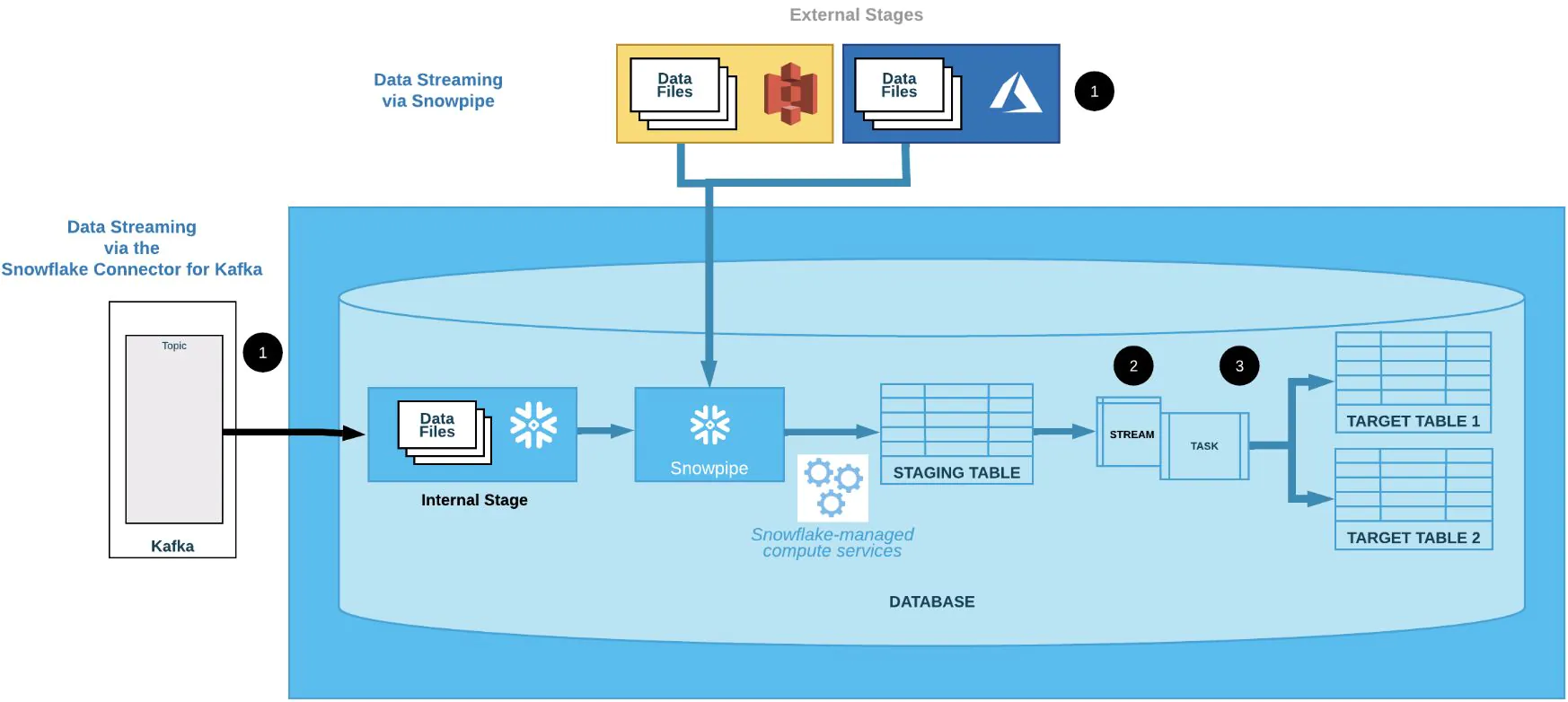
Snowpipe
Snowpipe continuously loads micro-batches of data from an external stage location (Amazon S3, Google Cloud Storage, or Microsoft Azure) into a staging table.
Snowflake Connector for Kafka
The Kafka connector continuously loads records from one or more Apache Kafka topics into an internal (Snowflake) stage and then into a staging table using Snowpipe.
One or more table streams capture change data and make it available to query.
One or more tasks execute SQL statements (which could call stored procedures) to transform the change data and move the optimized data sets into destination tables for analysis. Each time this transformation process runs, it selects the change data in the stream to perform DML operations on the destination tables and then consumes the change data when the transaction is committed.